We use the speech-only portion of the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) which consists of 1440 samples:
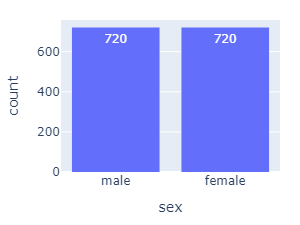
Actor Sex
Recorded by 24 actors:
- half female, half male
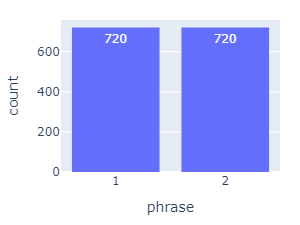
Phrases
- Phrase 1: "Kids are talking by the door."
- Phrase 2: "Dogs are sitting by the door."
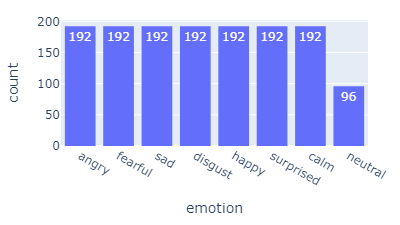
Emotions
- neutral, calm, happy, sad, angry, fearful, disgusted, surprised
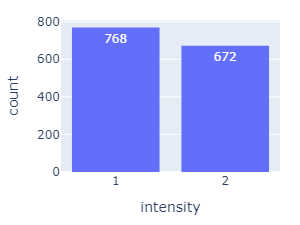
Intensity
Each statement is expressed using each emotion twice:
- once at lower intensity
- once at higher intensity
- The emotion category "neutral" only has 1 intensity, hence the uneven distributions in both the emotions and intensities.
Data Pre-Processing
Before moving to the feature extraction process, we reduce the size of our data by trimming each sample to 2.5 seconds and resampling the file to 16kHz.
Trimming removes the silence at the beginning and allows us to work with smaller files, resulting in faster feature extraction and training. For our purposes, the silence at the beginning doesn't contain any useful information.
We downsample the examples from 48kHz to 16kHz for similar reasons. There's not much speech information above 8kHz, so we can get rid of that information and in the process, we are feeding the model more of the information that's important to our application and less of the noise.
Validation Process
Each sample was rated by individuals from a pool of 349 participants ten times. Information on perceptual validation can be found here.
Next:
Continue to learn about feature extraction.